Controllable audio synthesis is a core element of creative sound design. Recent advancements in AI
have made high-fidelity neural audio synthesis achievable. However, the high temporal resolution
of audio and our perceptual sensitivity to small irregularities in waveforms make synthesizing at
high sampling rates a complex and computationally intensive task, prohibiting real-time, controllable
synthesis within many approaches. In this work we aim to shed light on the potential of Conditional
Implicit Neural Representations (CINRs) as lightweight backbones in generative frameworks for
audio synthesis.
In generative modelling data is generally represented by discrete arrays. However, the true underlying signal is often continuous. Implicit neural representations (INRs) are neural networks used to approximate low-dimensional functions, trained to represent a single geometric object by mapping input coordinates to structural information at input locations. INRs have several benefits compared to most discrete representations:
The required amount of parameters to faithfully represent an object is independent of resolution, and only scales with its complexity.
Object samples are calculated independently, allowing sequential or targeted synthesis in memory- or computationally limited environments.
Our experiments show that Periodic Conditional INRs (PCINRs) learn faster and generally produce quantitatively better audio reconstructions than Transposed Convolutional Neural Networks with equal parameter counts. However, their performance is very sensitive to activation scaling hyperparameters. When learning to represent more uniform sets, PCINRs tend to introduce artificial high-frequency components in reconstructions. We validate this noise can be minimized by applying standard weight regularization during training or decreasing the compositional depth of PCINRs, and suggest directions for future research.
Reconstructing Sets of Waveforms as Continuous Functions
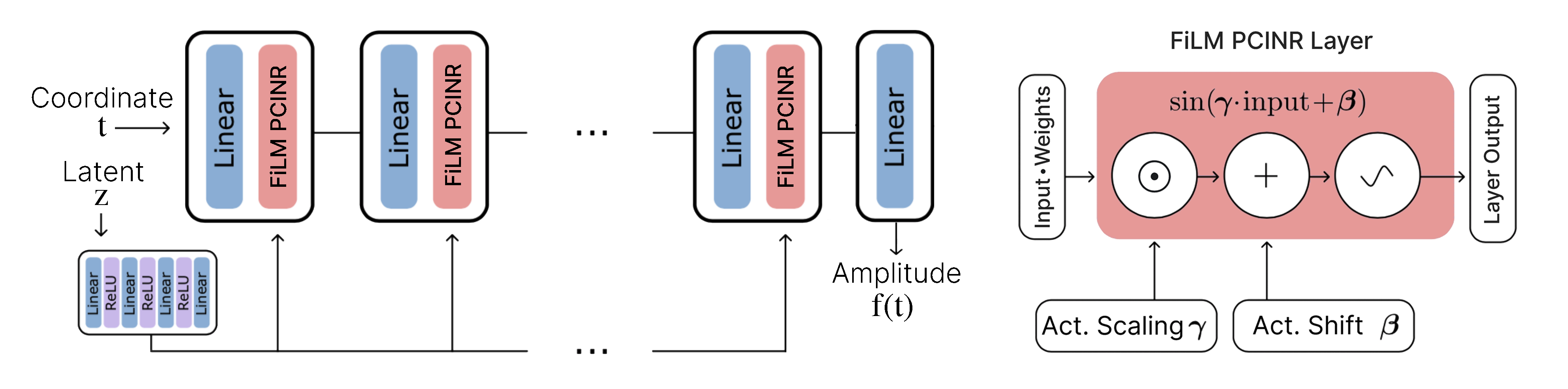
To apply INRs in the generative domain we frame generative modelling as learning a distribution of continuous functions. This can be achieved by introducing conditioning methods to INRs. We refer to this family of architectures as conditional INRs (CINRs). In this work we focus on layer activation modulation [1] as the conditioning method.
The dominant architectures in INR literature are MLPs with traditional nonlinearities. This class of networks is biased towards learning low-frequency functions. Recently, the usage of periodic nonlinearities in INRs has proven to be effective at circumventing this bias [2]. This increased expressiveness creates potential for applying INRs in the domain of audio.
To gauge the potential of CINRs for controllable audio synthesis we compare the ability of CINRs with periodic nonlinearities (PCINRs, based on π-GAN [3]) and transposed convolution neural networks (TCNNs, based on WaveGAN [3]) to reconstruct two 1024 item sets of waveform samples.
Results
Quantitative Results
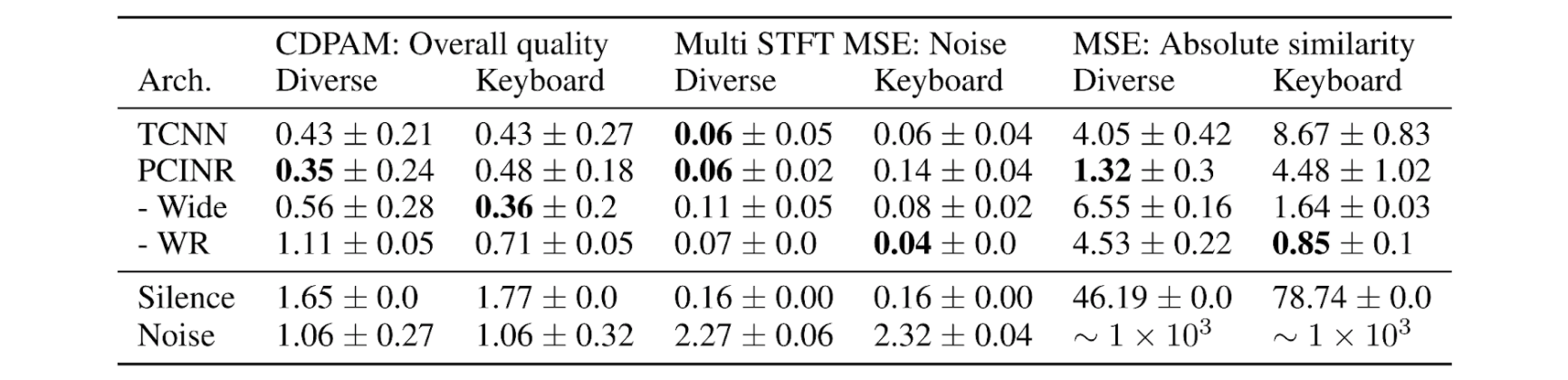
Three quantitative evaluation metrics are reported based on our metric correlation comparison [5]: CDPAM [6], Multi STFT MSE and MSE. The table below shows these scores for NSYNTH Diverse and NSYNTH Keyboard over all set items, calculated over 3 training runs.
PCINRs outperform baseline TCNNs consistently on MSE.
For the other, more perceptual metrics, PCINRs are outperformed by TCNNs in reconstructing the NSYNTH keyboard dataset.
With regularization (L2 weight regularization for INR weights or reducing INR compositional depth) PCINRs beat TCNNs in these scenarios.
Samples
Comparing results qualitatively, PCINR outputs are less muffled than TCNN outputs, but contain some high frequency noise. Regularized PCINR outputs contain less noise, but also sound more muffled.
Ground truth
TCNN
PCINR
PCINR Wide
PCINR WR
Conclusions & Future Directions
PCINRs with FiLM conditioning exhibit exceptional expressivity, making them suited for modelling distributions of high-frequency one-dimensional continuous functions such as audio waveforms.
PCINRs are capable of modelling more details than TCNNs, but also induce more local inconsistencies in the output signal.
Performance is very sensitive to activation scaling hyperparameters. Optimal hyperparameter values depend strongly on data characteristics.
Weight regularization and compositional depth offer additional control over expressiveness and can further improve output quality.
Periodic nonlinearities with high scaling factors contain a high density of stationary points, which cause locally inconsistent signal propagation. We argue this significantly impedes learning in PCINRs, and that it is an important cause for the observed local inconsistencies in reconstructions. Implementing INRs as parallel subnetworks could counter this behavior.
Bibtex
@article{zuiderveld2021towards,
title={Towards Lightweight Controllable Audio Synthesis with Conditional Implicit Neural Representations},
author={Zuiderveld, Jan and Federici, Marco and Bekkers, Erik J},
journal={arXiv preprint arXiv:2111.08462},
year={2021}
}
References
[1] Perez et al. (2017). “FiLM: Visual Reasoning with a General Conditioning Layer.” arXiv: 1709 . 07871
[2] Sitzmann et al. (2020). “Implicit Neural Representations with Periodic Activation Functions.” arXiv: 2006.09661
[3] Chan et al. (2020). “Pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis.” arXiv: 2012.00926
[4] Donahue et al. (2019). “Adversarial Audio Synthesis.” arXiv: 1802.04208